6.2 Constructing a Confidence Interval for a Population Proportion
6 min read•june 18, 2024
Jed Quiaoit
Josh Argo
Jed Quiaoit
Josh Argo
AP Statistics 📊
265 resourcesSee Units
A confidence interval is a range of values that is calculated from sample data and is used to estimate a population parameter. In the case of categorical data, a confidence interval is used to estimate a population proportion. 🔸
The confidence interval is based on the sample proportion, the sample size, and the sampling distribution of the sample size. The sampling distribution is the distribution of the sample statistic (in this case, the sample proportion) that would be obtained if we were to take multiple samples from the population and calculate the sample statistic for each sample.
The confidence level is a measure of how confident we are that the confidence interval contains the true population parameter. In other words, our confidence interval is reliant on a confidence level, which impacts how confident we are that our interval contains the true population proportion. The standard confidence level is usually 95%.
As the confidence level increases, the width of our interval also increases. ⬆️
Checking Conditions
Random Sample
This reduces any bias that may be caused from taking a bad sample. When answering inference questions, it is always essential to make note that our sample was random, either by highlighting text on the exam, or by quoting the problem where it details its randomness. Without a random sample, our findings cannot be generalized to a population. This means that our scope of inference is inaccurate. There are no calculations that can fix an un-random, or biased, sample. 📚
Independence
This ensures that each subject in our sample was not influenced by the previous subjects chosen. While we are sampling without replacement, if our sample size is not super close to our population size, we can conclude that the effect it has on our sampling is negligible. We can check this condition by questioning if it is reasonable to believe that the population in question is at least 10 times as large as our sample. 🤔
For example, if we have a random sample of 85 teenagers math grades and we are creating a confidence interval for what the proportion of ALL teenagers passing their math class, we could state, "It is reasonable to believe that there are at least 850 teenagers currently enrolled in a math class."
To sum this idea up: When sampling without replacement, check that n ≤10%N, where N is the size of the population. A good way to state this when performing inference is to say, "It is reasonable to believe that our population (in context) is at least 10n." 💡
Normal
This check verifies that we are able to use a normal curve to calculate our probabilities using either empirical rule or z scores. We can verify that a sampling distribution is normal using the Large Counts Condition, which states that we have at least 10 expected successes and 10 expected failures.
In the example listed above, let's say that we were given the proportion that 70% of all teenagers pass their math class. That means that with a sample of 85, 0.75(85)=63.75, which is greater than 10. We also have to check the complement by calculating 0.25(85)=21.25, which is also greater than 10.
Since both np and n(1-p) are greater than or equal to 10, we can conclude that the sampling distribution of our proportion will be approximately normal. 🎉
One Sample z-interval for Proportions
A one-sample z-interval for a proportion is an appropriate procedure for constructing a confidence interval for a single population proportion based on a sample of categorical data. This procedure uses a z-test to estimate the population proportion based on the sample proportion and the sample size. 😳
The one-sample z-interval for a proportion is used when the following conditions are met:
- The sample is a random sample, or the sample size is large enough (usually n > 30) to use the normal approximation to the binomial distribution.
- The data are collected from a single categorical variable, such as a yes/no response or a dichotomous variable.
- The sample size is large enough to use the normal approximation to the binomial distribution.
- The population proportion is unknown and needs to be estimated from the sample data.
To construct a one-sample z-interval for a proportion, the sample proportion and sample size are used to calculate a z-score, which is then used to determine the confidence interval. The confidence interval is calculated as the sample proportion plus or minus a multiple of the standard error of the proportion. The standard error of the proportion is a measure of the variability of the sample proportion and is calculated using the sample size and the population proportion (which is assumed to be equal to the sample proportion).
Calculating the Interval
Calculating a confidence interval is based on two things: our point estimate and our margin of error.
(1) Point Estimate
The point estimate for a confidence interval used to estimate a population proportion is the sample proportion, which is also known as the p-hat. The sample proportion is the estimate of the population proportion based on the sample data.
The sample proportion is the middle point of the confidence interval and is used to calculate the confidence interval bounds. 📱
As you'll see later, the confidence interval bounds are calculated by adding and subtracting a multiple of the standard error of the proportion to the sample proportion.
(2) Margin of Error
The margin of error is the "buffer zone" of the confidence interval and is used to allow for the possibility of error or uncertainty in the estimate of the population parameter. his is what we add and subtract to our sample proportion to allow some room for error in our interval. The standard error of the proportion is a measure of the variability of the sample proportion and is calculated using the sample size and the population proportion (which is assumed to be equal to the sample proportion).
The margin of error is based on the critical value (z-score), which is a value that is determined by the confidence level, and the standard deviation of the sampling distribution, and standard deviation. The critical value is the number of standard deviations that the sample statistic is from the population parameter. For example, if the confidence level is 95%, the critical value is usually 1.96.
The sample size has a significant impact on the margin of error. As the sample size increases, the standard deviation of the sampling distribution decreases, which results in a smaller margin of error. This means that as the sample size increases, the confidence interval becomes narrower and the estimate of the population parameter becomes more precise. 🎯
Formula and Some Notes
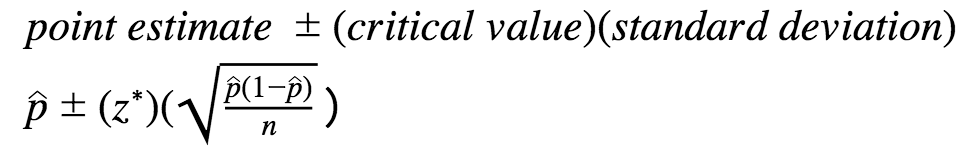
Note that the formula for the margin of error can be rearranged to solve for the minimum sample size needed to achieve a given margin of error. The formula for the margin of error is:
Margin of error = z * standard error of the proportion, where z is the critical value and the standard error of the proportion is calculated using the sample size and the population proportion (which is assumed to be equal to the sample proportion).
To solve for the minimum sample size needed to achieve a given margin of error, we can rearrange the formula as follows:
n = (z / margin of error)^2 * p * (1 - p), where n is the minimum sample size, z is the critical value, margin of error is the desired margin of error, p is the population proportion (which is assumed to be equal to the sample proportion), and 1 - p is the population proportion of the other category.
If you are trying to find an upper bound for the sample size, you can use a guess for p or use p = 0.5 in order to find the maximum sample size that will result in a given margin of error. This will give you an idea of the maximum sample size that you would need in order to achieve the desired margin of error. ❤️
Using a Calculator
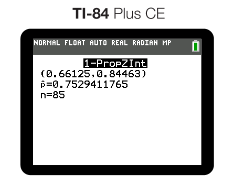
A much easier, more efficient way of calculating a confidence interval is to use a graphing calculator or other form of technology. When using a graphing calculator such as a Texas Instruments TI-84, you would select 1-Prop Z Interval from the Stats menu, enter your number of successes (x), sample size (n), and confidence level. Lastly, calculate and you will get the confidence interval you requested! 🖥️
🎥 Watch: AP Stats - Inference: Confidence Intervals for Proportions
Browse Study Guides By Unit
👆Unit 1 – Exploring One-Variable Data
✌️Unit 2 – Exploring Two-Variable Data
🔎Unit 3 – Collecting Data
🎲Unit 4 – Probability, Random Variables, & Probability Distributions
📊Unit 5 – Sampling Distributions
⚖️Unit 6 – Proportions
😼Unit 7 – Means
✳️Unit 8 – Chi-Squares
📈Unit 9 – Slopes
✏️Frequently Asked Questions
📚Study Tools
🤔Exam Skills
© 2024 Fiveable Inc. All rights reserved.